
I am constantly bombarded on LinkedIn by AI news: a new protocol specification is out, here people are automating everything with agents, here are agents replacing a whole team of highly experienced neurosurgeons, etc.
I look at this with fascination, but also with some scepticism (especially around the claims that it’s a done deal and all problems are resolved). And as a result, I decided to experiment and write a couple of simple agents.
Let me share two short stories before I dive into building agents.
“Convert this image to PDF.”
I had a simple image (a picture of one page) with a lot of text, some of which required style formatting that I needed to convert to PDF. I would probably have tried to find a tool that specializes in such conversions and used it in the past. However, this time around, I decided to use ChatGPT to do that.
I dropped an image in there, and it spit out a PDF. The good thing was that the PDF contained all the text; the bad thing was that there was no formatting at all. It was just four pages of text, one line after another (instead of having one one-pager).
I asked it (second prompt) to structure it the same as in the original image, but it failed.
As a result, I spent probably the next 30–40 minutes telling it, prompt by prompt, what to do (move this column a bit to the right, add indentation here, change the color of this text to red). And probably over a dozen or so prompts, I got it looking similar to the original.
First of all, it’s impressive that it was able to understand my prompts, and we got to a nice place. However, the obvious problem is that I had to spoon-feed and spend more time on it than if I had searched and used a specialized tool.
A quick sidetrack: I am sure there are some people who spent last year much more deeply immersed in this area, who would be quick to say, “Oh, you are using the wrong provider, model, prompt, etc.” On one hand, it easily could be true, but on the other hand, my experience is extremely representative of how things will go for the absolute majority of the population (even those who have reasonable user-level LLM experience).
“Build a simple Rails app.”
Second was my attempt to do vibe coding. I wanted to build a simple Rails app. I downloaded Cursor and tried to use it.
First, I asked it to generate a Rails app, and it immediately fell on its face. Apparently, something went wrong on my machine, and it was unable to find Rails (while it was installed). It suggested running certain commands to fix the issue. The first command was sane, and I did that (and it didn’t fix anything), the second command was a bit more intrusive, and the third was getting into an insanity zone (which would probably corrupt my Homebrew setup).
I rolled up my sleeves, did some Googling, and in 10 minutes, everything was fixed by adding a single symlink.
After that, it was able to generate a Rails app. I asked it to add some scaffolding, which it did well.
Rails apps usually come out of the box looking like a high school kid’s project (terrible UI). I asked it to apply some modern UI style. It added Tailwind (which is nice), but after that, it completely messed up the view. I tried multiple prompts to fix it, but it went literally nowhere. And I quickly realized that I was spending WAY, WAY more time than if I were doing this myself.
I did a bit more experimentation, but I felt like I was working with an extremely junior intern who had memorized all these commands and patterns, yet had absolutely no idea what they were doing. I had to guide it step by step, constantly reminding it of the goal and not to forget things, and slapping its hands when it tried to execute sudo rm -rf /*.
Overseer and Critic
I believe my experience is not unique at all. LLMs often can produce results that look like magic (getting in minutes seemingly to 80% of some task), and after, you have to cajole and spoonfeed them to get the remaining 20%, quite often pointing out some trivial problems.
That’s where my idea about creating agents came together.
I wanted to build three agents:
- Initial solution generator
- Critic
- Fixer
I would send a prompt to the first one, and it would take my problem and generate an (unpolished) idea. The second one receives the original prompt and idea generated by the first and writes a critique of it. The last one receives the idea, solution, and critique and responds with an updated solution. The critic and the fixer bounce back and forth until either the critic says “good enough” or the fixer says “can’t fix this”.
My hope was twofold: to gain experience in agent building and hopefully break out of the loop of reviewing and overseeing what LLM does.
Building Agent
Where Does LLM Inference Run?
First things first. I knew that my experiment could end up quite prompt-intensive. For example, at one point, I left it running for an hour and doing prompts. I was concerned that I would exceed some API limits or reach my plan’s quota. So, I decided to run the LLM locally.
Considering that my notebook is a Mac, I found that I have several options: Ollama, LM Studio, llama.cpp, and a few others.
I landed at LM Studio. The main thing that I liked was that it provided quite a nice UI.
What Model Should I Run?
LM Studio has a curated list of about 40–50 models (which is already not a trivial choice). However, it doesn’t end there. It can directly get things from Hugging Face. In such a case, enjoy spending eternity choosing a model (out of almost 2 million! models).

I don’t even remember how (I believe again with the help of ChatGPT) I landed on Google’s Gemma 3 12B model.
BTW, even understanding the name of the model requires learning some of the LLM alphabet soup. If you are not familiar with it, take a look at this article.
Agent Framework
The next choice is what kind of framework you want to use to build your agent.
Based on the research, I had several choices again:
- CrewAI
- LangGraph
- Microsoft AutoGen
- CAMEL
I decided to use CrewAI because it was touted for “Good balance of structure and flexibility.”
I won’t bore you with a blow-by-blow account of getting it up and running. The biggest issue I ran into was configuring it to work with my LLM:
I had code that looked like this.
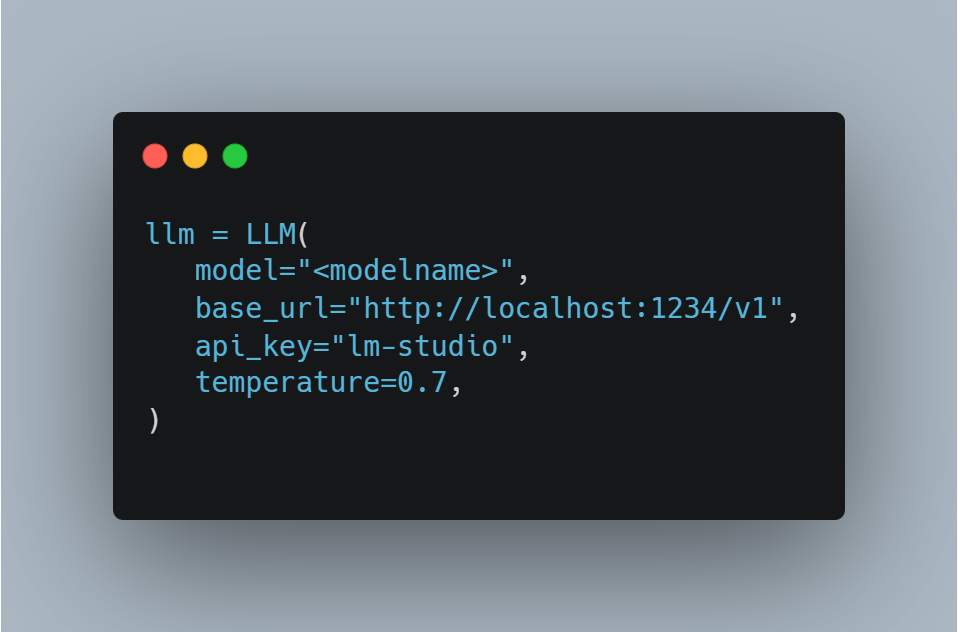
And it was complaining that this results in bad requests. I spent an untrivial amount of time trying to figure it out, and ChatGPT sent me (multiple times) on a wild goose chase. Until I went into Google and started carefully reading articles on this subject, I quickly realized that the model name should be formatted as “openai/<modelname>” to indicate that it should interact with it via OpenAI-compatible endpoints (/v1/chat/completions, etc.).
As soon as I got this working, things started to move forward quicker.
Tools
Although MCP is all the rage now, I added web search to the agent the old-fashioned way. And the minimalistic agent looked like this:
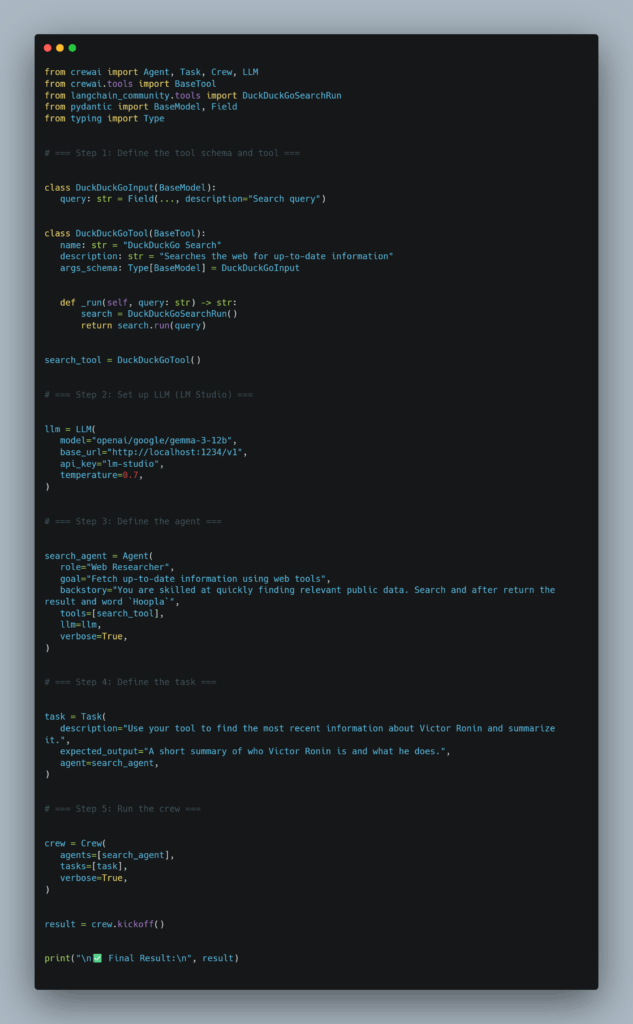
The interesting part is that although it worked, the result of running this trivial agent ended up being very different in quality.
Some of the runs were nice (it gathered information from LinkedIn, my Medium blog, and a couple of other sources), and the summary was good. Another time, it ended up extremely low quality (finding some small pieces of irrelevant information from the past and grabbing some parts of my Medium articles and trying to summarize them into some strange mix).
Multiple Agents
After that, I defined multiple agents as described before (initial solution generator, critic, and fixer). As I was working through that, I realized that CrewAI is designed for more linear task execution. So, you have a task list, and agents work on these tasks. CrewAI has a notion of conditional tasks, but I haven’t found what I imagined (a workflow with looping over tasks or microservice-like message communication).
I had to write some Python code to make it happen and get it working the way I wanted, with three agents working and two of them kicking things back and forth.
Debugging
I quickly noticed that these agents are not actually calling the web search tool (as they’re supposed to), which led me to start debugging the LLM inputs and outputs.
This (ability to see inputs and outputs) appears to be a critically important feature for agent development. However, it actually ended up being underbuilt.
LM Studio via the command line only allows you to see LLM input. And if you view logs via the UI, input is truncated, but output is available. You have to piece it together from the LM Studio CLI log streaming and the UI.
There were two things that absolutely blew my mind:
- What actually LLM gets as the final input (vs original prompt)
- LLM issues when it tries to call the search tool
This is how an input appeared for the trivial test agent I showed above. I highlighted the sections that are user-defined (meaning coming from the agent code).
I would strongly recommend reading through the LLM input. It’s amazing how much crud has accumulated in it. First, these things start with start_of_turn, end_of_turn, which are OpenAI chat capabilities related info. Second, it involves the definitions and explanations of how to use the tool. Third is Thoughts/Action/Observation/FinalAnswer — a pattern implemented by CrewAI based on the ReAct paper. And there are some other fillers.
As you read through it, tell me: Would you (as a human) be able to understand the task well? 🙂
By the way, the only reason the LLM can handle all of this because it has been trained on similar data. And LLM output is actually also in this Action/FinalAnswer format. And somewhere in the agent framework layer, something strips down these “Final Answers” and so on, showing you (the user) only the text.
Here is the LLM input (passed by that simple agent code shown above):
<bos><start_of_turn>user
You are Web Researcher. You are skilled at quickly finding relevant public data. Search and return the result and the word `Hoopla`
Your personal goal is: Fetch up-to-date information using web tools
You ONLY have access to the following tools, and should NEVER make up tools that are not listed here:
Tool Name: DuckDuckGo Search
Tool Arguments: {‘query’: {‘description’: ‘Search query’, ‘type’: ‘str’}}
Tool Description: Searches the web for up-to-date information
IMPORTANT: Use the following format in your response:
“`
Thought: you should always think about what to do
Action: the action to take, only one name of [DuckDuckGo Search], just the name, exactly as it’s written.
Action Input: the input to the action, just a simple JSON object, enclosed in curly braces, using ” to wrap keys and values.
Observation: the result of the action
“`
Once all necessary information is gathered, return the following format:
“`
Thought: I now know the final answer
Final Answer: the final answer to the original input question
`“
Current Task: Use your tool to find the most recent information about Victor Ronin and summarize it.
This is the expected criteria for your final answer: A short summary of who Victor Ronin is and what he does.
You MUST return the actual complete content as the final answer, not a summary.
Begin! This is VERY important to you, use the tools available and give your best Final Answer, your job depends on it!
Thought:<end_of_turn>
<start_of_turn>model
As I mentioned. Another thing I found is that the LLM got lost in this instruction (plus, instead of the highlighted parts, there was quite a lot of additional text on the problem, solution, and criticism, which were specific to my agent tasks).
Frankly, I don’t blame the LLM. I got lost reading these layers of instructions on top of each other. It was too much for it to handle, and as a result, it often generated both the answer and action simultaneously (which CrewAI didn’t comprehend as an action and treated as plain text, passing it to my next agent).
I got the whole thing limping, but it ended up working quite unpredictably and bumpy, and at that moment, I ran out of time, which I had allocated for this exercise
The uncomfortable truth is that while everyone seems to be talking about building skyscrapers with LLMs, my experience suggests they're laying foundations on quicksand.
Thoughts
Now, let me go back to my favorite analysis style. Let’s tease apart what was the good, the bad, and ugly.
Good
If you think about it, a person with quite basic knowledge in this area can now, within a single day, figure out how to run LLM, integrate it, create multiple agents that use natural language, integrate it with tools, and get this whole thing off the ground.
Yeah. It was a bit bumpy, it was proto-typy and hacky. However, again, all of it was done in one day.
If you think about it, five years ago, you would require a team of top Ph.D. scientists, a couple of years, and I don’t know how much money to achieve such results, and now it’s a weekend project.
Bad
The paint is incredibly fresh on everything around LLM and especially the agents.
Any article older than six to nine months is half-outdated. The UX of most of the tools is subpar.
Things are kind of integrated with each other. However, you can see parts of duct tape sticking out at the site of integration.
Ugly
As I was working through all of this, an unpleasant realization dawned on me (triggered by my agent’s incorrect response, which combined both answer and action, when they should be done mutually exclusively).
Pretty much, this experience was a refrain of my experience with PDF conversion of vibe coding.
People (including me) were using chat apps and LLMs a lot for the past several years, and often (too often for business needs), LLM responses were wrong. And there was a human in the loop to figure it out and make the necessary fixes. The industry moved to agents and tools. And LLMs are still often incorrect, and humans are still involved in correcting them.
We are now moving into an autonomous multi-agent architecture. And LLMs will still often be wrong, but now humans are no longer in the loop to correct them. What can go wrong?
All these agent frameworks, tools, and the MCP server are plumbing. True business logic is LLM, and the prompt is hardcoded into your agent.
The uncomfortable truth is that while everyone seems to be talking about building skyscrapers with LLMs, my experience suggests they’re laying foundations on quicksand. Lightweight projects might hold up for a while, but anything more complex or built without human oversight tends to sink quickly.
Better prompting in the agent won’t fix these errors. No amount of automatically adding to prompt sentences like, “This is VERY important to you, use the tools available and give your best Final Answer, your job depends on it!” will make it less error-prone. And the frameworks and MPC won’t fix these errors either.
My fixer agent was “smart” only in its name, but it could not have said… “Whoa… Stop the train, this whole thing looks off….”, which person would have done immediately.
The ugly part. It’s damn hard to build software which fails often and even error handling (if you replace a human by LLM in the loop) is probabilistic.
Wrong Model / Wrong Prompt / Poor Finetuning
This is a good opportunity to revisit the argument above. I can see how people can point out that I should use better models and better prompts. This is both true, but also a bit nearsighted. For example, at some point, I considered switching from instruction models to chat models. It can/will decrease the probability of error in each step, but I don’t think that it solves the overall problem of multi-step processes where each step increases the probability of errors.
I would agree more with this argument if the current error rate were 3% and the acceptable rate was 2%. In such a case, you can see how you try to optimize everything to get as close to 2%. However, overall, the high-end models still have a 10-20% error/hallucination rate (depending on the subject domain), while an acceptable rate for many business activities is significantly lower, and pure optimization alone won’t close this gap.
Guardrails and Negative Feedback Loop
If you think about this, humans are also quite fallible. How do multi-human processes work in such a case?
I think there are three reasons why it works:
- First of all, you assign the most consistent people to the most critical part of the process. Your anesthesiologists (thankfully) don’t often hallucinate the amount of drugs that need to be injected. Compare this to LLMs, where even the best ones have much, much higher error rates than professionals.
- Humans operate with a negative feedback loop. If you do something (important) incorrectly, you end up with consequences. Apparently, our natural (as opposed to artificial) neural network is much faster at auto-correcting. So, people try to avoid doing important things badly. For LLMs, there is no distinction between “life-or-death” prompts and casual chat. They are all pretty much the same.
I think what works for LLMs is when they can at least test their response. For example, an agent attempts to call an API and fails, resulting in an error being returned to the LLM. However, even this has limited value, because often they get lost in root-cause analysis and have a hard time identifying what doesn’t work.
It’s exactly the problem that I mentioned earlier. It’s remarkable how ChatGPT, equipped with search, was unable to identify the root cause of my Rails failure and essentially got stuck in a guessing game (with the potential to mess up my development environment even more).
Summary
First of all, you may ask a valid question: you just spent one day on this, so why do you think you know it better than people who spent a year?
The answer is: I don’t.
However, I am not the only person who is talking about error rates, edge cases, error handling, and the need for human oversight (to successfully achieve goals). I believe my experience is not a fluke, but rather a norm.
Additionally, I’ve been in the tech industry for a substantial amount of time, and I know how to build demos. I could have easily spent several more days building a compelling demo, announcing that I created a full-blown negative feedback loop (using my critic agent) and that my solution solves LLM errors. I could have recorded a nice video showing how it solved some task (after failing off-camera 10 times to solve the same task). In essence, I could have hyped up the solution rather than discussing it objectively and pragmatically.
I think I will keep being skeptical until I see:
- Out-of-the-box agents have low error rates
- Big enterprises are adopting agents and spending some time with them (to get feedback from users, customers, partners, and so on)
As it stands now, I could imagine delegating (for autonomous execution) low-risk, low-to-medium-value tasks. I would not delegate any high-risk, high-value tasks to agents yet. And I think this aligns well with what we see in the wild. There are tools that capture meeting notes, FAQ chatbots, email drafting for low-stake communication, content classification, and internal knowledge search bots.
All of them nicely fall into the low-risk, low-to-medium-value tasks category. And I haven’t seen successful companies around more high-risk tasks.





