



Modern infrastructure runs on workloads: microservices, data pipelines, CI/CD jobs, serverless functions, containers, and increasingly, autonomous AI agents.
Every one of these workloads needs to authenticate to something, whether a database, a cloud API, a SaaS platform, or a model provider, and do so continuously, at machine speed, without a human in the loop.
This is a fundamentally different problem from user identity. Users log in once, establish a session, and interact in ways that are relatively predictable. Workloads authenticate thousands of times per day, run in ephemeral environments that spin up and disappear in seconds, and have no ability to respond to an MFA prompt.
Agentic AI systems compound this further: They chain together multiple services, make decisions autonomously, and require access policies that can reason about what an agent is doing, not just who it is.
Most organizations already have user IAM and PAM systems in place, and the natural instinct is to reach for them first. The problem is that these tools were designed around human identity: session lifetimes, approval workflows, password vaults, and privileged access consoles built for operators who sit at a keyboard.
Customers tell us that when they try to stretch these systems to cover workloads and AI agents, they hit the same capability gaps: no native support for cryptographic workload attestation, no way to enforce short-lived credential issuance at the access layer, and audit trails that capture user sessions but cannot reconstruct which workload accessed which resource under what policy.
This is not a failure of the tools. It is a mismatch between what they were built for and what workload identity actually requires. And it is not just PAM and IAM products that organizations are trying to repurpose; Teams are reaching for whatever they already have, including secrets managers, service meshes, and API gateways, with similar results.
Why Not Build Your Own Workload IAM Solution?
When the existing tooling falls short, the next step is usually to build something. That decision is reasonable. The primitives exist. The platform team is capable. And the first version is almost always straightforward enough to make it seem like building was the right call.
We have talked to hundreds of engineering teams across industries and company sizes who have been down this road.
The pattern is consistent: The first version works. A service can now fetch a secret from a vault. A pipeline can authenticate to a cloud API. The early results are good enough that the project gets resourced. Then the second service comes online, and then the third, and the team starts to discover that what they built for one environment does not transfer cleanly to another. A Kubernetes deployment works differently from an AWS Lambda function, which works differently from a GitHub Actions workflow, which works differently from a legacy VM running on-premises.
Each gap requires a decision: Extend the system, work around it, or accept the inconsistency. The scope of what needs to be built keeps growing, and the original estimate, which accounted for none of this, starts to look like a different project entirely.
Getting a working prototype is well within reach. Making it production-grade is a different project, one that most teams do not fully scope until they are already committed to it.
Here is what “building it” actually means, what it costs to maintain, and why most teams that build it eventually wish they hadn’t.
What a Production-Grade System Actually Requires
When teams start scoping a workload identity system, they typically think about the deployment mechanism first: how will workloads actually receive credentials? There are three main approaches, and most teams start with one before discovering they need the others.
An SDK or library approach embeds credential-fetching logic directly into application code. Each service calls the identity system, retrieves the appropriate credential, and manages its own refresh lifecycle. This is often where teams start, as it is the most direct path from zero to working and requires no additional infrastructure. The limitation surfaces at scale: every application becomes an active participant in the credential lifecycle, every onboarding story requires a code change, and every new target system or credential type requires updating code across multiple services.
A CLI approach moves credential retrieval out of application code and into a command invoked at runtime, which is useful for scripted workflows, batch jobs, and CI/CD pipelines where an SDK integration is impractical. This works well for specific workload types but does not address the broader problem of credential management across a mixed environment.
A proxy approach introduces a transparent layer that intercepts outbound requests from workloads and injects credentials automatically, without requiring changes to application code. This solves the code-change problem that plagues SDK-based approaches and makes onboarding new services operationally much simpler. Teams often migrate to a proxy after experiencing the friction of the SDK model at scale.
Getting to Production-Grade Adds Complexity
Even though the proxy approach solves some issues, it introduces its own constraints. A proxy can run as a sidecar or local daemon alongside workloads in Kubernetes, on VMs, or in containerized environments, but it cannot run inside a SaaS-based CI/CD platform.
GitHub Actions, GitLab-hosted runners, and similar environments do not allow you to deploy a sidecar. The jobs are ephemeral, the infrastructure is managed by the vendor, and the only integration point available is an SDK or CLI.
CI/CD pipelines are a primary workload type, and organizations need workload identity to work consistently whether a job is running on a self-hosted Jenkins instance where a proxy is viable, or on a SaaS platform where it is not. A system that handles one but not the other forces teams to maintain two parallel approaches, and that is before accounting for the rest of the deployment surface.
Most teams that build their own workload identity system end up needing all three approaches. The SDK handles the cases where a proxy cannot run. The CLI covers scripted and pipeline workflows. The proxy handles the broad population of services where code changes are unacceptable.
Building and maintaining all three, with consistent policy enforcement, a shared attestation model, and a unified audit trail across every deployment type, is where the scope of a homegrown project grows well beyond what the original estimate anticipated.
The five engineering layers described below are not optional once you commit to production-grade coverage.
The Day 1 / Day 2 Problem
Writing code to fetch a secret is easy. A few lines, a vault SDK call, a stored API key.
Day 1 is fine.
Day 2 is where the project starts to accumulate debt.
The credential has to rotate, and something has to orchestrate that without breaking the workload. A new service needs access to a different target system with a different token format, which means another integration to build.
An auditor asks for a complete record of which workload accessed what, when, and under which policy, and the logs are scattered across four cloud providers. A SOC 2 assessor asks for evidence of least-privilege access enforcement, and the homegrown system has no concept of policy at all.
The maintenance tax compounds quietly. Every hour the platform team spends on the identity proxy is an hour taken away from the product work that differentiates the business.
Five Layers. Most Teams Scope It as One.
A production-grade workload identity system is not a single project. It has five distinct engineering layers, and most build estimates only account for the first.
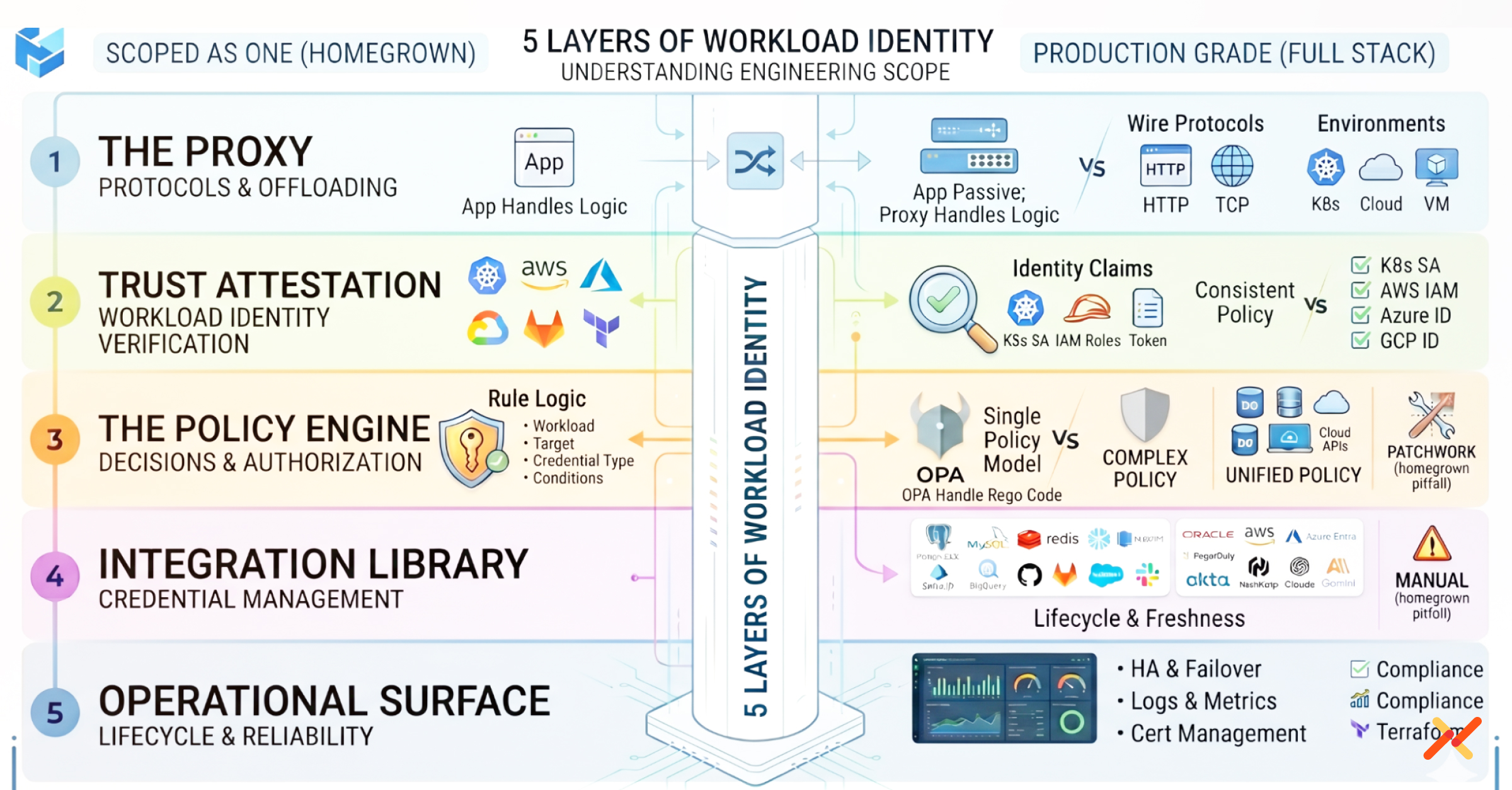
The Proxy
Teams that skip the proxy do not escape the work; they move it into every application and by extension onto the plate of every developer. Without a transparent proxy layer, credentials have to be injected directly into application code: each service gets its own SDK call, its own credential-fetching logic, and its own refresh implementation.
That adds a code change requirement to every onboarding and integration story, and it means every application becomes an active participant in the credential lifecycle rather than a passive beneficiary of it.
The alternative is a transparent proxy that speaks the wire protocol of every target system. Not just HTTP but also Postgres, MySQL, Redis, Amazon Redshift, and Oracle Database and others.
Each requires its own protocol-aware parser and credential injector. And the proxy has to run everywhere workloads run: Kubernetes, AWS ECS Fargate, AWS Lambda, Linux VMs, Windows VMs, Docker Compose, VMware. CI/CD pipelines add another dimension of complexity.
Self-hosted platforms like Jenkins can run a proxy alongside the job, but SaaS platforms like GitHub Actions and GitLab-hosted runners cannot. Those environments require a separate SDK or CLI integration maintained in parallel, with its own attestation logic and credential lifecycle. Building equivalent coverage from scratch is a multi-year engineering project. Operating without it means a multi-service code change project instead.
Trust Attestation
Before the proxy issues a credential, something has to cryptographically verify that the calling workload is who it claims to be. That requires environment-specific attestation logic for every platform in the stack: Kubernetes service accounts, pod names, and namespaces; AWS EC2 instance IDs, ECS task families, Lambda ARNs, and account IDs; Azure subscription and VM IDs; GCP identity tokens; GitHub and GitLab ID token claims; Terraform Cloud workspace and organization IDs; process names, paths, and command lines on VMs.
Each identifier has to be maintained as cloud provider metadata APIs evolve. A homegrown system typically covers one or two environments at launch and accumulates gaps from there.
The Policy Engine
Access decisions require a rule evaluation engine that combines workload identity, target system, credential type, and conditional access controls in a single real-time decision. Teams reach for OPA, which requires learning Rego, building a policy authoring interface, operating the OPA deployment, and writing custom evaluation logic for every access condition.
The complexity also compounds across integrations. When a team builds against a single target service, they can often map their access rules to that service’s native policy model without too much friction. The problem surfaces as the number of integrations grows.
Each new target system has its own policy primitives, its own authorization model, and in many cases no real policy engine at all.
A homegrown system has to either build custom policy logic per integration, tightly binding each one to whatever that service exposes, or accept that some services will have no meaningful access control beyond authentication.
The result is a patchwork: rigorous controls where the target system cooperated, and gaps everywhere else.
Aembit enforces a single policy model at the access layer, before the request reaches the target system, which means policy coverage is consistent regardless of whether the downstream service has a policy engine of its own.
The Integration Library
Every target system that workloads need to reach requires its own credential integration: the right token format, the right header injection, the right refresh lifecycle.
Organizations require integrations across databases, cloud services, SaaS APIs, developer tools, and AI providers, including PostgreSQL, MySQL, Redis, Snowflake, Amazon Redshift, Oracle, AWS services, Azure Entra ID, GCP BigQuery, Databricks, GitHub, GitLab, Salesforce, Slack, Stripe, PayPal, Atlassian, PagerDuty, HashiCorp Vault, Okta, OpenAI, Claude, Gemini, and more. Integrations need to be continuously tested and updated when upstream APIs change.
The Operational Surface
This is what the build-vs-buy analysis almost always misses: high availability and failover for the proxy and controller, certificate lifecycle management, support matrix maintenance as new Kubernetes versions and OS distributions release, audit log pipelines to SIEM systems, a compliance dashboard, a Prometheus-compatible metrics endpoint, and a Terraform provider for policy-as-code. None of this is exciting to build.
All of it is load-bearing.
Three Problems That Compound over Time
The Secret Zero Problem
Building a workload identity system yourself almost always surfaces a chicken-and-egg problem: how do you securely authenticate the workload that is supposed to retrieve its own credentials? You need a credential to get a credential. Teams solve this with a hardcoded bootstrap secret, an instance metadata call, or a Kubernetes service account, each of which is a trust assumption that has to be validated, maintained, and secured. The attack surface you were trying to close reopens at the bootstrap layer. Aembit eliminates this by attesting workload identity cryptographically at the moment of access, with no bootstrap credential required.
Policy Orchestration Across a Real Environment
A policy engine that works for Kubernetes does not automatically work for Snowflake, AWS Lambda, GitHub Actions, and a legacy on-premises database in a different region. Each environment has different identity primitives, different token formats, and different access models. A homegrown policy engine either gets rebuilt per environment or forces everything through the lowest common denominator. Neither approach scales. Aembit enforces a single policy model across every environment, from Kubernetes to CI/CD to Lambda to legacy on-premises systems, without lowest-common-denominator compromises.
The Audit and Compliance Trap
DIY solutions routinely fail SOC 2 and FedRAMP audits not because the security model is wrong but because the evidence does not exist. Auditors ask for granular, identity-centric access logs, proof of least-privilege enforcement, and tamper-proof trails showing which workload accessed which resource under what policy. A system assembled from OPA policies, custom proxy logs, and per-service audit events across multiple cloud providers cannot easily produce that evidence. Aembit logs every access event with full attestation context and streams those logs to Splunk, CrowdStrike SIEM, AWS S3, and Google Cloud Storage. Aembit’s global policy compliance dashboard maps policy state directly to SOC 2 and NIST frameworks.
Can I Use SPIFFE/SPIRE to Build This?
SPIFFE is an open standard for workload identity, and SPIRE, its reference implementation, is real infrastructure built by engineers who lived through the credential sprawl problem at scale.
For a greenfield, Kubernetes-native environment with a dedicated platform team, SPIRE can meaningfully address the trust attestation layer described above: workloads get cryptographic identities, secrets are replaced with short-lived SVIDs, and the bootstrap credential problem shrinks considerably. Where SPIRE helps most, it genuinely helps.
The honest question is what it does not cover, and for most enterprise environments, that list is long. SPIRE requires deploying and maintaining a stack of eight to ten interdependent components alongside it: SPIRE agents on every node, a high-availability SPIRE server backed by a shared database with KMS-protected CA keys, an Envoy proxy with Secret Discovery Service configured per workload to handle the proxy layer, OPA for policy decisions SPIRE has no concept of, and a management UI that the core project does not ship. None of these components share a release cycle, and keeping them mutually compatible is ongoing work in itself.
More fundamentally, SPIRE does not reach the integration library or the SaaS access problem at all. Snowflake, Salesforce, and GitHub do not run SPIRE agents and do not validate SVIDs. Every SaaS integration still requires OAuth tokens, API keys, or other credential types managed entirely outside the SPIFFE trust model. CI/CD pipelines on hosted platforms like GitHub Actions cannot run a SPIRE agent, so the proxy layer falls back to an SDK or CLI maintained in parallel.
On-premises workloads lack the signed instance metadata that makes cloud-based attestation elegant, and legacy applications that cannot call the SPIFFE Workload API require SPIFFE-helper sidecars that add their own operational weight.
Defakto, the company founded by the engineer who ran one of the world’s largest SPIFFE deployments, puts the timeline for a production-grade SPIRE deployment at six to 24 months depending on environment complexity, and then raised $49 million to wrap it in a commercial product because the open-source path was too hard to operationalize at enterprise scale. SPIRE is a strong foundation for the attestation layer. It is not a substitute for the other four.
See our Everyone Wants SPIFFE. Almost No One Can Afford to Build It Right.
What it looks like side by side
Capability | DIY / Build Yourself | Aembit |
Workload authentication | Hardcoded secrets, env vars, or bespoke bootstrap logic | Workload-native attestation: SPIFFE, OIDC, cloud IAM, Kubernetes, GitHub/GitLab, Terraform Cloud |
Credential rotation | Manual or custom scripts; breakage risk on every rotation | Automated and transparent to the application |
Policy enforcement | All-or-nothing access, or OPA with Rego and a custom authoring interface to build | Just-in-time, least-privilege access with built-in UI and Terraform provider |
Multi-service policy consistency | Policy rebuilt per integration; each binds to that service’s model (or no model at all) | Single policy layer enforced before the request reaches any target system |
Multi-environment support | Rebuild per environment; Kubernetes, Lambda, VMs, and CI/CD are all different problems | Single policy model across all deployment types |
Target system integrations | Each new system is a separate development project | 35+ integrations shipped and maintained |
Conditional access | Custom integration to each posture provider | Native CrowdStrike, Wiz, GeoIP, and time-based controls |
Audit trail | Fragmented logs across clouds in different formats | Centralized, identity-centric log for every access event |
Compliance evidence | Manual assembly for each audit | Global policy compliance dashboard aligned to SOC 2 and NIST |
Operational burden | Dedicated engineering headcount for maintenance and HA | SaaS-delivered updates |
AI agent support | Build OAuth 2.0 flows for MCP from scratch | MCP Authorization Server, Identity Gateway, and blended identity included |
Are You Already Past the Point Where DIY Makes Sense?
If you are managing credentials across more than two environments, if more than one engineer’s job touches the identity proxy, if a compliance review has surfaced gaps in your access audit trail, or if the engineer who designed your trust model has left or is planning to, the maintenance tax is likely already affecting your roadmap.
The longer a homegrown system runs, the more embedded it becomes and the more disruptive it is to migrate away from. The teams that migrate successfully do it before the scale wall hits, not after.
Talk to an engineer about what a migration from a homegrown system looks like in practice.
You can find a full integration list and support matrix at docs.aembit.io.




