

Over the last six months, the world has gone from zero to 60 mph on agentic AI.
I’ve been a fairly avid LLM user (for software development, polishing text, and other needs). However, I’ve barely touched on agentic AI, model context protocol (MCP), and other modern approaches that have popped up recently.
For those of you like me who aren’t yet deep into this topic: agentic AI is about giving AI the ability to take action, not just respond to prompts like traditional chatbots. It can plan, make decisions, use tools, and often collaborate with other AI agents like a team, rather than acting as a lone assistant.
Right now, I’m working on figuring out authentication for this area. As part of that, I’ve read a bunch of articles, experimented, and built some prototypes (which will soon be productized and open-sourced).
One thing became clear as I talked to colleagues: If you haven’t looked into this space recently, you might already be behind the curve from a mental model standpoint.
In this post, I want to lay out a step-by-step explanation, starting from the basics and building on top of them. So, if you’re an engineer like me who didn’t spend the last year knee-deep in this space, you can get up to speed quickly, without having to dig through a ton of details just to reconstruct the high-level picture.
Disclaimer: The first part might be too basic for folks already deep in the space. If that’s you, feel free to skip ahead to the ‘Authentication’ section.
High-Level Architecture
LLM
These are the standard components we’ve been dealing with in most common LLM apps over the past few years (ChatGPT web app, Claude Desktop, VS Code Copilot extension):
- LLM
- An application (either browser-based or native) that uses the LLM
- LLM API (for LLMs running as a service)

This is nice and simple and pretty much looks like any frontend/backend application.
Agents
The new thing that was added recently is agents. The basic components: app, LLM, and LLM API haven’t changed, but the app itself has evolved. It’s no longer just a pass-through chat interface. It has become more complex and autonomous.
Think of it as an app that runs in a loop, has some memory (context) of what it’s done before (prompts and their responses), and calls the LLM via LLM API repeatedly, each time with new prompts based on the results of the previous ones, until this agent reaches its goal.

One note: At the core, all an LLM does is take in text and return text. On its own, that’s not very useful until it can interact with services like file systems, the web, databases, or APIs. That’s why people started building ways for agents to hook into those services..
This is the biggest mental model trap into which I (and others) stumbled.
People often assume that the LLM itself has access to services. But, in reality, the LLM just does text in/text out. It’s passive. It doesn’t reach out to anything. Instead, companies (especially those offering LLMs as a service) have built additional components that act as agents, reaching out to services, running loops, and prompting the LLM multiple times, among other actions.
All of these are done under the hood (behind the LLM API). As a result, it’s easy to get the impression that the LLM is doing it.
If you are familiar with ChatGPT research or web search functionality, it’s implemented on the backend side.
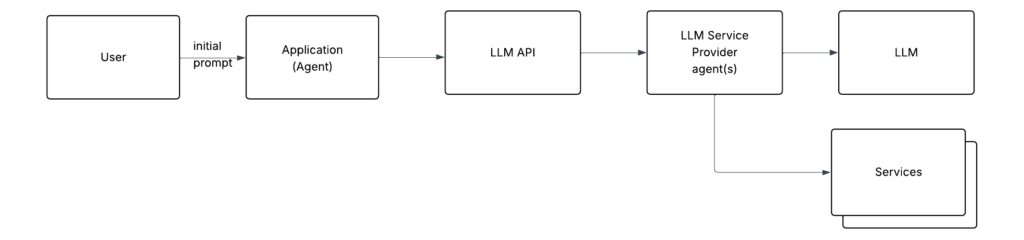
Back to agents (under the user’s direct control): Integrations with services are embedded in the agent
When the agent calls the LLM, it includes something like the following in the prompt: “If you want me (the agent) to access resource/service X, use the following response format.”
If the LLM returns a response formatted in that specific way, the agent interprets it as an action (a request to interact with the service) versus literal text. The agent executes it (by accessing that service) and sends the results of the execution back to the LLM.
Since this article focuses on aspects of agentic authentication under user or developer control, I’ll omit the interactions of LLM service provider agents from the remaining diagrams. They operate as black boxes, outside our control in terms of architecture, configuration, and authentication
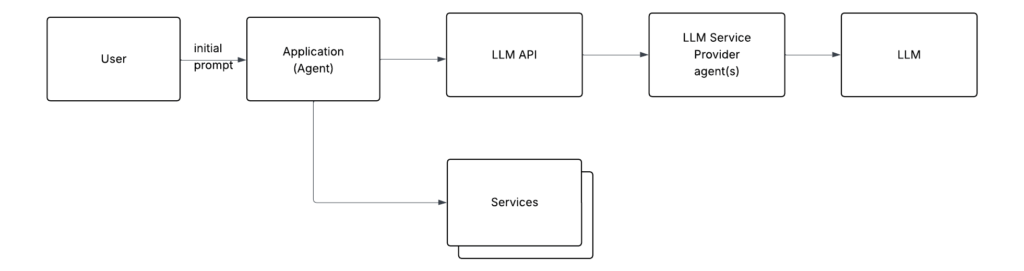
Agents integrating with services works well, but it creates a problem: every agent developer ends up re-implementing integrations from scratch (or at least using SDKs for these services) and figuring out the same concerns (finding SDK in appropriate language, configuring SDK, authentication, often secrets management, letting LLM know how to structure response so the agent knows it’s time to use the service, etc).
That’s where the Model Context Protocol (MCP) came in. It standardizes how to integrate with services. Imagine your agent needs access to Salesforce. Instead of implementing custom logic, it simply connects to an MCP server that already knows how to communicate with Salesforce, instantly gaining the ability to read leads, contacts, and accounts.
All an agent needs to do is tell the MCP client (embedded in the app) where the MCP servers are located, specifying both the location and transport. The MCP client handles most of the heavy lifting: connecting to the MCP server, authenticating, discovering its capabilities, exposing them to the agent, and defining how they should be communicated to the LLM.
And here’s the critical part. The MCP protocol defines how the MCP Server exposes its interface to the MCP Client. This includes details like the list of tools and their parameters, and so on. The agent, using the MCP client, retrieves this interface information, converts it (using the method defined in MCP) into text, and sends it to the LLM. This lets the LLM know that the agent has gained new capabilities via the MCP server.
While solving the problem of inconsistent integrations was important, the real breakthrough was introducing a standard way to communicate available interfaces to the LLM.
And the beauty of it is that it all works in a consistent way, regardless of the specifics of each service the MCP server connects to.
It’s a classic adapter pattern applied really well in this case. (MCP is widely called “USB-C for AI applications,” implying that you can plug in any new MCP server and it just works.
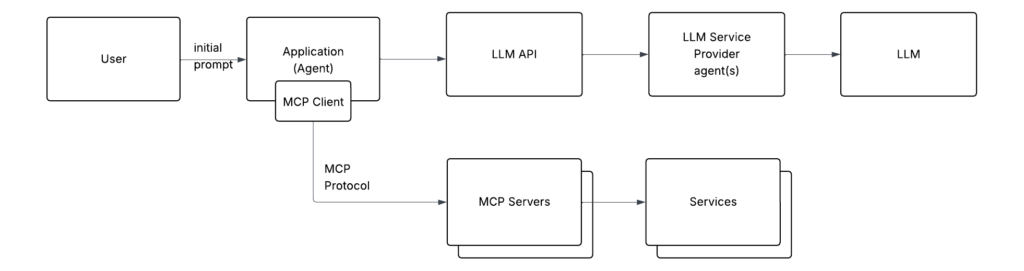
An additional benefit of this approach is that it moves the whole set of concerns (like configuring new integrations, figuring out what actions the integration can do) from design time (when you are developing your agent) to runtime. Just point to an additional MCP server, and the MCP client will figure out the rest.
Everything I’ve said up to this point is a bit of a simplification. There are some permutations of this picture:
- LLMs may run locally versus remotely, in which case you can potentially bypass the API layer.
- There could be additional components between the LLM API and the LLM (on the LLM service provider side) that can provide extra functionality
- Even though MCP is standardized, you’ll still need a language-specific SDK to integrate it with agents written in different programming languages
However, ignoring these extra details, the last diagram shows where the center of mass of what many people are doing is located. It allows people to build agents with their own functionality, easily integrate with additional services without relying on providers like OpenAI to build out these integrations on the server side.
And finally, this pattern allows one agent to talk to other agents (also via MCP) to build more complex logic. So, the full picture of multi-agent interactions may look something like the following:
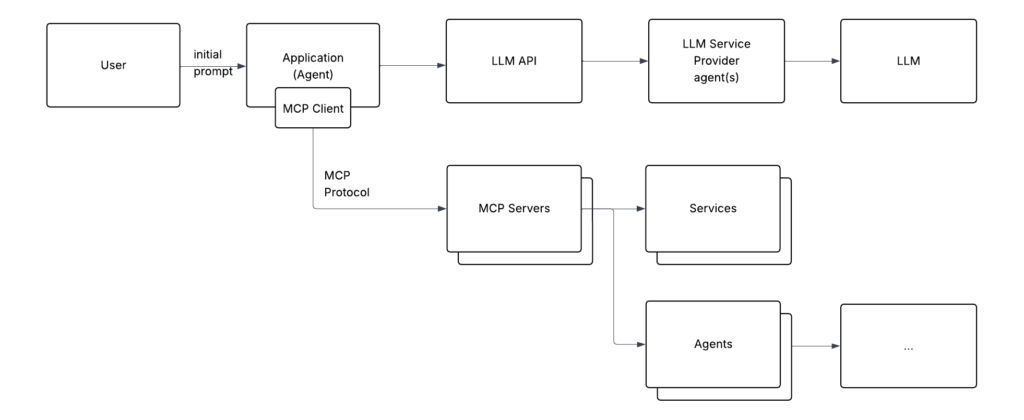
You can draw analogies with microservices. Each agent is a microservice that can communicate with either other microservices or external services.
This section covered how agents, LLMs, MCP servers, and services interact with each other. Next, I’ll walk through authentication and authorization between these components, including how it works and the known complexities involved.
Authentication
One note before we move into authentication and authorization. Just to show how quickly things are evolving. I began working on this post in early June, and by the middle of the month, a new specification of the MCP protocol was released, which invalidated a paragraph I had included regarding the complexities of MCP servers interacting with third-party authorization servers. As a result, some of these items (especially around MCP) may capture just the current point in time.
Now that you’re familiar with the high-level architecture, let’s dive into the next layer: authentication between the different components.
Here’s the same diagram as above, showing three trust boundaries (marked with dotted lines). Authentication needs to happen each time communication crosses these boundaries.
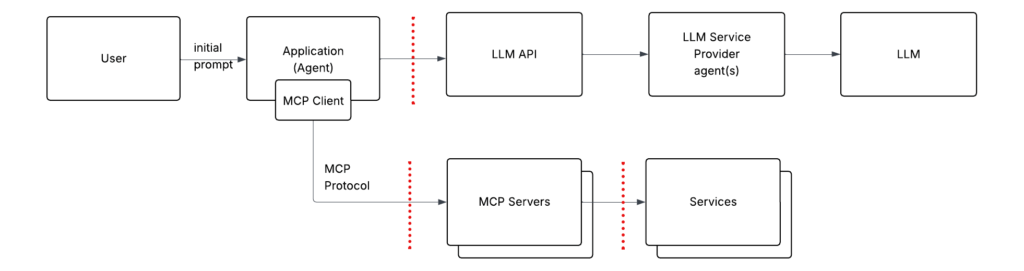
Let’s walk through all three trust boundaries and go over common authentication approaches used in each.
1) Application → LLM API
This is vendor-specific. That said, in most cases, you’ll see:
A user is asked to do social login with Google, Facebook, etc. They go through the OAuth flow and get appropriate tokens.
Side note: managing these (OAuth, OIDC) tokens in frontend apps is a whole Pandora’s box of security concerns. And different applications solve it differently. However, that’s outside the scope of this article, but worth calling out.
Yes, long-lived secrets are still a thing. You generate an API key from your LLM provider, paste it into your app or agent—and just like that, you’ve now created the headache of securing and managing that secret.
Again, this is all vendor-specific. Companies can basically do whatever they want.
2) MCP Server → Service
This is technology-specific. While the previous case most likely involves HTTP(S)-based auth protocols and a high probability that auth credentials will end up in the Authorization header, the MCP server-to-service trust boundary has much more variety.
If the MCP server talks to a database, you’ll need to use the database’s authentication method. If it talks to an old Kerberized app, then you’re in Kerberos land. And if your service is a 1993 Siemens S7 PLC sitting in a water treatment plant, well, good luck figuring out how to handle that one securely.
3) MCP client (embedded into the application) → MCP server
Now the new fun part. There’s a spec for the Model Context Protocol, and Kevin Sapp wrote a really nice overview of it. If you dig into the spec, it mandates (if you are doing auth) usage of OAuth 2.1 (which is still a draft).
If you’re not familiar with OAuth 2.1, you can think of it as a tighter version of OAuth 2.0, with insecure options deprecated and most security-improving approaches (like PKCE) being mandated.
But the paint’s still wet, for both the MCP protocol and OAuth 2.1, so a lot of implementations took shortcuts while the industry figures things out.
In practice, most MCP servers I checked out are running on the same machine as the MCP client. The MCP client launches the MCP server process and communicates with it over stdio with no authentication at all. It’s the easiest path, but also a risky one, pulling unknown MCP server code and running it locally, often with the same privileges as your app.
Oh… and any application on your computer can call this MCP server too (since no auth is required).
A smaller number of MCP servers use API keys or other shared long-lived secrets (which, by the way, don’t align with the latest spec).
And finally, a very small minority are actually implementing OAuth 2.1 according to the specification.
A note on the previous several paragraphs: this is a snapshot in time. I’m sure the ratio will drastically change over the next year as the number of ready-to-use and fully functional MCP clients and MCP servers skyrockets and people start integrating them into their agents.
Authorization
Application → LLM
As it stands, the authorization here is coarse-grained. You are either authorized to use the LLM or not. My guess is that it will most likely continue that way.
MCP Server → Service
Given that this interaction could involve any technology or protocol, the authorization scheme is necessarily technology-specific. As such, it’s not possible to provide a universal description. Each technology implements its own mechanisms, which vary widely in design and complexity.
MCP client (embedded into the application) → MCP server
Here we have fine-grained authorization controlled by an OAuth authorization server. A user authenticates to the authorization server, which issues access tokens with specific scopes that control what the client can do.
Authorization Complexities
This section touches on a lot of subjects Kevin Sapp (Aembit’s CTO) discussed in “Self Assembling AI and the Security Gaps It Leaves Behind.”
Delegation
As soon as you have a chain of calls,e.g., application (with MCP client) → MCP server → service, you want the second component (MCP server) to act on behalf of the first one (application).
It’s a classical delegation problem (nothing new here, even though LLMs and agents are involved).
This problem is somewhat mitigated in modern, heterogeneous environments (for example, when the entire chain supports OAuth). But it’s not solved when there’s a technology mismatch. In such cases, the downstream service acts on its own, rather than on behalf of the upstream caller.
I think it will remain that way. Most likely, the industry will figure out agent-to-agent delegation. However, as soon as the MCP Server reaches out to external services, it will use its own identity, not that of the originating user or agent.
There are new developments like the Grant Negotiation and Authorization Protocol, which try to go beyond OAuth in this area. But we’ll have to wait and see if it gains adoption.
Dynamic Permissions
In the past, software could be described as static; you knew what it was supposed to do ahead of time. It was granted the necessary permissions, and no more, adhering to the least-privilege principle.
It’s getting more complicated with agents relying on LLMs to decide what action comes next.
Example: let’s say your company serves an international market, and you decide to write an agent to translate all customer support tickets into English. Initially, you think read-only access to the ticket system is enough. But no, you also need write access to put the translations back. Then the agent discovers that large attachments are stored in an S3 bucket. Now it needs read/write access to that. Later, it hits a ticket that’s locked and can’t be modified. The agent decides to create a copy, and now it needs permission to create new tickets.
In the past, developers would identify these needs during development and coordinate to bump permissions accordingly.
Now, the same use cases are discovered and handled dynamically by the agent. And the more agents you have, and the smarter they are, the more they’ll push the envelope. There’s no clear answer yet on how this will be handled.
Blend of User and Machine Identity
Imagine the following scenario. You have an agent that interacts with the HR system. You’re an authorized user and ask for the number of employees. The agent tries to count them but finds some records where the employee/contractor status is missing.
The agent finds documentation that says a missing status implies an employee. The agent (via MCP) attempts to query with an empty string, but the HR system doesn’t allow it. So the agent decides to update the empty status fields to “employee”, which turns out to be wrong, because the documentation was outdated. Notice how a trivial read-only operation turned into a destructive update.
Now ask yourself: who’s responsible for this change? The user or the agent?
Should the agent perform the action using the user’s permissions, since the user is allowed to make such a change, or should it act under its own, more limited set of permissions, which might block the change entirely? Whose identity should be used when actions like this are taken?
In this case, it feels like it should have been the agent’s identity. But it’s easy to come up with a use case where you’d say it should have been the user’s.
How do we create a blend of the two, granting enough permissions to allow the necessary actions, while restricting what shouldn’t be done, while keeping both the user and the agent accountable?
This is a brand-new problem, and no obvious solution exists yet.
What’s Next?
At first glance, agentic AI might feel familiar. Many of the challenges around authentication and authorization seem similar to what we’ve seen in traditional full-stack apps.
However, agents powered by LLMs push us into new territory, where old assumptions about architecture, integration, and security begin to break down.
As we build more capable, autonomous systems, authentication and authorization aren’t just implementation details. They become core building blocks that shape what is possible and what is safe. The landscape is still evolving, standards are still solidifying, and best practices are still being discovered.
This guide is just a snapshot. Expect the picture to change quickly.






