

Key Takeaways
-
The MCP Authorization Spec introduces an OAuth 2.1 + PKCE-based model for agentic AI access control.
-
Agentic systems create unique challenges: dynamic behavior, no user in the loop, complex accountability.
-
PKCE protects token exchanges — but does not authenticate the client.
-
Strong identity for non-human clients depends on infrastructure-asserted identity.
-
Conditional access and ephemeral tokens reduce risk and improve control.
Agentic AI systems – where large language models (LLMs) power autonomous, goal-driven agents – are rapidly transitioning from experimental prototypes to production-ready services.
These agents read databases, trigger API calls, write to software-as-a-service (SaaS) platforms, and stitch together workflows across systems that weren’t necessarily designed to coordinate. As these systems evolve, a fundamental question remains: How should identity and access be handled when no human is in the loop?
Initially introduced by Anthropic, the Model Context Protocol (MCP) provides a standardized interface for agents to interact with external tools, prompts, and resources. It has the potential to become the lingua franca for agentic interoperability. But as agent actions become more powerful — and potentially more dangerous — robust, flexible, and secure access control becomes essential.
The recently released MCP Authorization Specification proposes an essential first step: standardizing how clients obtain authorization to access protected MCP resources using OAuth 2.1 and PKCE (Proof Key for Code Exchange).
This post unpacks what the spec introduces, why PKCE was chosen, how the flow works, and why authentication remains a critical missing piece, especially in non-human entity interactions.
Why Agentic AI Needs a New Authorization Model
In traditional web architectures, authorization typically involves browser-based login flows, session cookies, or OAuth tokens issued after a human clicks “Authorize.”
Agentic AI systems present unique authorization challenges because they make autonomous API calls driven by LLMs, without direct user involvement. These agents interpret prompts and programmatically plan tasks, necessitating strong API security measures. Typically long-lived, stateless, and dynamic, these agents operate without user oversight for access approval or execution guidance.
This change creates some challenges:
- Dynamic behavior: The agent may decide at runtime which tools to use.
- Non-human actors: There may be no user to complete an OAuth flow.
- Security risks: Access tokens must be scoped and rotated in ephemeral, cloud-native environments.
- Complex accountability: Agents often blend delegated user authority with autonomous action, blurring the audit trail. Further, agents can interact with one another, and this inter-agent communication significantly complicates accountability and entitlements.
The MCP authorization specification attempts to impose structure on one part of this problem: How should an MCP client discover and obtain access to protected resources?
Goals of the MCP Authorization Specification
The spec introduces a consistent, standards-based authorization workflow for MCP clients. Its goals are to:
- Decouple access control logic from MCP servers by deferring to a trusted OAuth 2.1 authorization server.
- Standardize how clients learn about access requirements through Protected Resource Metadata (PRM).
- Secure token acquisition via the OAuth 2.1 Authorization Code Flow using PKCE.
- Simplify implementation by aligning with widely deployed identity infrastructure.
What’s in a PRM?
A PRM document is a JSON-based resource returned by an MCP server when access is denied. It typically includes:
{
"authorization_server": "https://auth.example.com",
"scopes": ["read:report", "tools:generate_summary"],
"token_types": ["Bearer"]
}
Why OAuth 2.1?
OAuth 2.1, currently an IETF working group draft, consolidates over a decade of security improvements from OAuth 2.0. Notable enhancements include:
- Deprecating the implicit flow, which exposed tokens via browser redirects.
- Requiring PKCE for all clients, including those capable of storing secrets (i.e., confidential clients). This enforces defense-in-depth and simplifies implementation guidance.
- Streamlining the spec by removing unused or confusing parameters.
- Ensuring TLS is mandatory and tokens are bearer-type.
These changes provide a secure and forward-looking baseline for MCP authorization flows.
How PKCE Protects Token Exchanges
PKCE plays a subtle but significant role in protecting token exchanges within Agentic AI systems. In traditional OAuth 2.0 flows, an attacker who intercepts the authorization code during redirection can exchange it for an access token. PKCE protects against this by requiring a shared secret (the code verifier) known only to the legitimate client. Specifically, PKCE, defined in RFC 7636, addresses the code interception threat in the OAuth 2.0 Authorization Code Flow.
It works as follows:
- The client generates a code_verifier (a cryptographically random string).
- It hashes this to produce a code_challenge sent in the initial auth request.
- The authorization server responds with an authorization code.
- To redeem this code, the client must present the original code_verifier.
- The server compares the hash and only issues a token if the match is valid.
This means that intercepting the code is not enough—an attacker would also need the original verifier, which is never sent over the wire.
PKCE is especially critical in MCP contexts where many clients, such as agents, containers, or serverless functions, are deployed in environments where storing secrets securely is difficult or infeasible. While PKCE does not replace client authentication, it enables public clients to use the authorization code flow securely without relying on a client secret, reducing the risk of token interception.
The MCP Authorization Flow, Step by Step
Here’s a practical example:
An LLM-powered agent receives the prompt: “Generate a sales summary for the past 30 days.” To complete the task, it needs to invoke the generate_summary tool exposed by an MCP server.
The sequence looks like this:
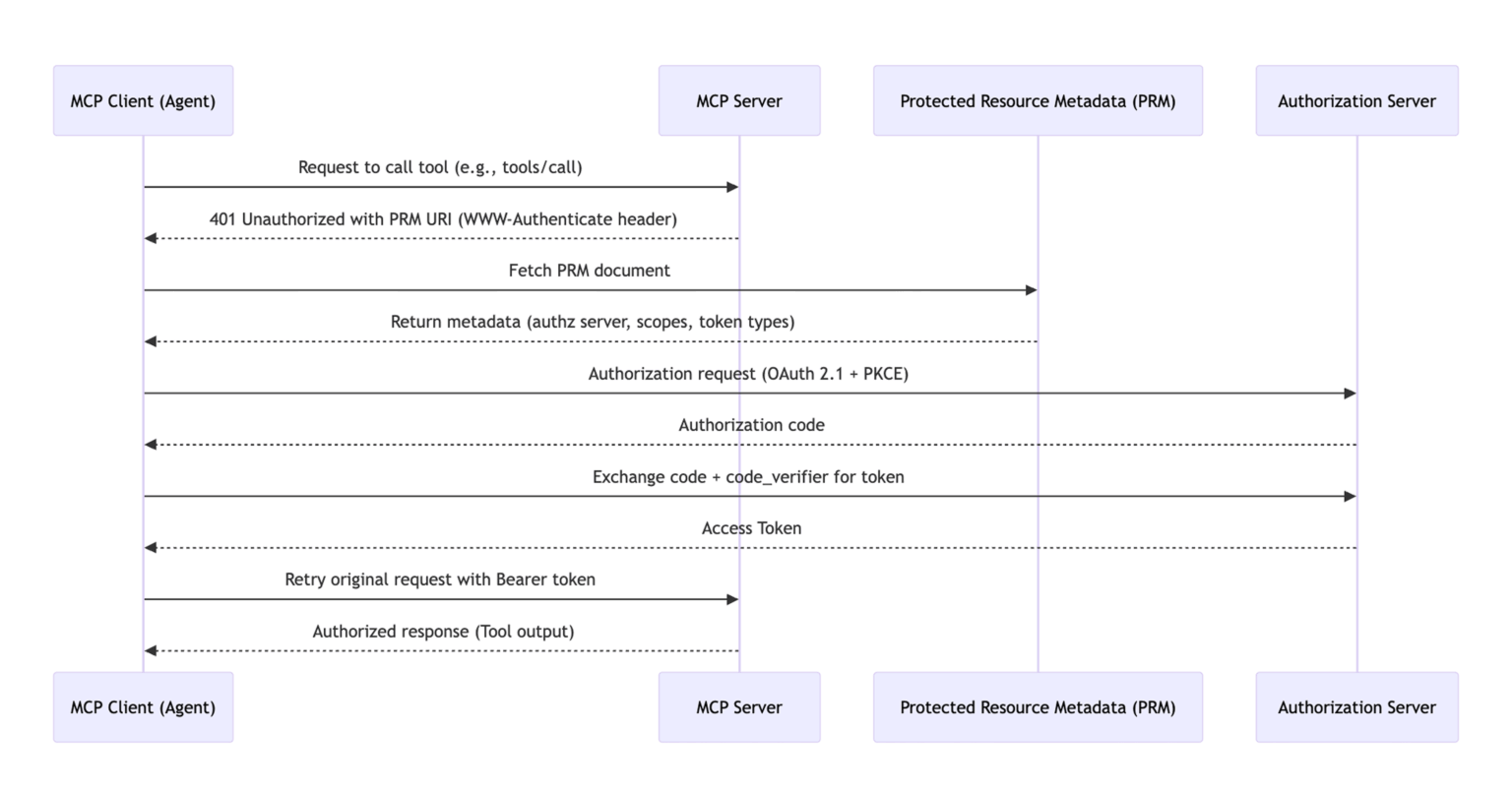
Let’s break that down:
- Initial Request: The agent sends a tools/call request to the MCP server.
- 401 Unauthorized: The server responds with WWW-Authenticate: MCP, including a PRM link.
- PRM Discovery: The client fetches the PRM and learns that it needs to obtain an access token from https://auth.example.com with scope tools:generate_summary.
- OAuth 2.1 Flow with PKCE:
- The client initiates the authorization request, including the code challenge.
- If a user is involved, they authenticate and approve access.
- If the client is acting on its own behalf, it should authenticate to the authorization server itself. But how is this done? We’ll discuss this scenario in more depth later in this article.
- Token Exchange: The client receives an access token.
- Retry: The client retries the original tools/call request with the token in the Authorization header.
What the Spec Leaves Open: Client Authentication
While the MCP authorization specification clearly defines the process for acquiring an access token, a critical aspect remains open: defining how non-human entities and autonomous workloads authenticate to the authorization server. This is a significant concern for platform engineers managing AI deployments who need to establish secure workload identities for these agents.
This is by design. MCP offloads identity enforcement to the authorization server, allowing implementers to choose authentication methods appropriate for their environment.
However, this creates a risk: If any unauthorized or unauthenticated process can initiate a PKCE flow, it could lead to the illegitimate issuance of access tokens and potential security breaches.
Why Strong Agent Authentication Matters
PKCE ensures the integrity of the token exchange, but it doesn’t prove who is making the request. Without strong client authentication, an unauthorized agent could misuse even a secure token flow.
In traditional OAuth flows, this is easy: a human logs in via SSO or MFA. But in agentic systems, there may be no human. The agent is a software system acting independently, sometimes with delegated authority, sometimes not.
Strong authentication mechanisms ensure that tokens are only issued to trusted workloads.
Infrastructure-Asserted Identity: A Better Way
Employing infrastructure-asserted identity is a powerful strategy for securing identity in agentic AI environments. This involves authenticating clients based on their runtime environment, such as cloud workload identities or Kubernetes service account tokens, rather than relying on static stored credentials or traditional authentication methods. This approach aligns well with modern cloud-native security principles.
Examples include:
- AWS IAM Roles assigned to serverless functions
- Azure Instance Metadata for virtual machines
- Kubernetes Service Account Tokens projected into pods
These mechanisms let the authorization server validate:
- The workload’s cloud or cluster origin.
- Its namespace, environment, or runtime labels.
- Its startup context or service role.
Conditional access policies should be implemented to enhance security after verifying the identity of a workload. These policies add a layer of protection by evaluating access attempts based on a range of factors beyond just identity. These factors can include the security posture of the host on which the workload runs, the time the access is requested, and the overall environment. Access conditions then dictate whether access is granted by taking this additional context into account, for example:
- Host security posture (e.g., is the node up-to-date and trusted?)
- Environment (e.g., dev, staging, or production)
- Time-of-day or geolocation
This two-layer model — identity first, context-based access conditions second — enables issuing ephemeral, scoped tokens tied to run-time characteristics, reducing reliance on long-lived secrets and improving security.
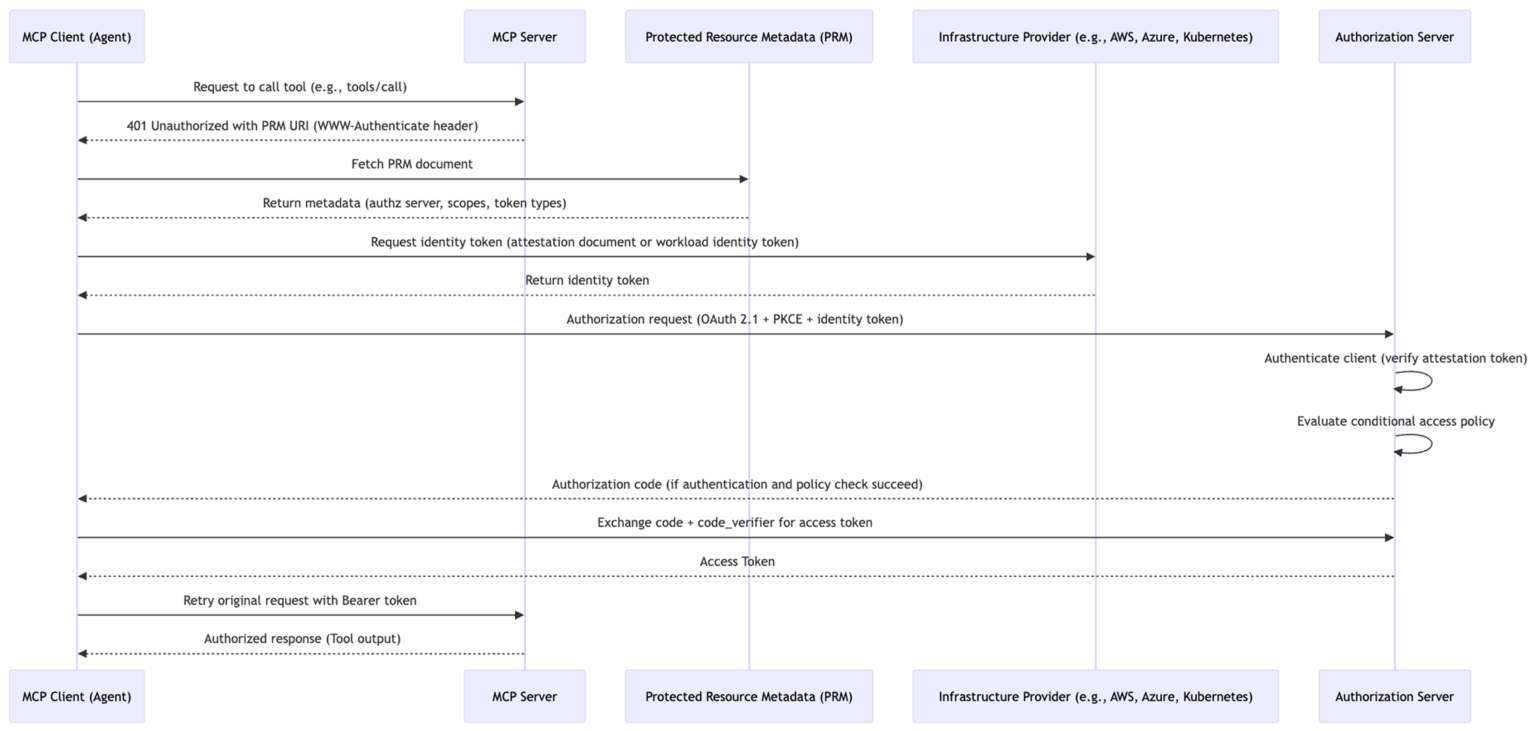
The following diagram builds on the previous one and includes the following steps:
- MCP client requests a native identity token from its infrastructure.
- MCP client presents its identity token to the authorization server.
- The authorization server authenticates the MCP client by verifying the identity token (attestation).
- The authorization server evaluates an access policy before issuing an access credential.
Best Practices for Agentic AI Builders
For software and security architects building agentic AI platforms, prioritize the following:
- Use PRM for discovery: Don’t hardcode endpoints or scopes.
- Require OAuth 2.1 with PKCE: Apply it universally, even to trusted clients.
- Prefer short-lived, scoped tokens: Reduce blast radius of compromised credentials.
- Authenticate clients via infrastructure: Use infrastructure-based attestation techniques to authenticate clients reliably in AI environments.
- Implement conditional access: Consider origin, time, posture, and behavioral indicators.
- Log extensively: Capture token issuance and, if possible, agent-tool interactions.
Final Thoughts on Authorization in Agentic AI
The MCP authorization specification is a strong foundation for securing agentic AI workflows. It offers a consistent, secure, and interoperable method for agents to obtain access to tools, prompts, and resources without reinventing the wheel.
But authorization is only part of the story.
Authorization is downstream of identity. And in the agentic ecosystem, identity is evolving fast. Standards like OAuth 2.1 and PKCE help us protect access flows, but we need strong authentication models to truly secure agentic systems, especially for non-human entities.
No vendor has it all figured out yet. But the combination of dynamic authorization and infrastructure-asserted identity is our most promising direction.
It’s time for builders — AI platform developers, infrastructure engineers, and security architects — to collaborate and define a comprehensive security architecture for agentic AI systems.
And robust authorization strategies and secure identity practices will be essential to building this trust in agentic AI systems.
The Workload IAM Company
Manage Access, Not Secrets
Boost Productivity, Slash DevSecOps Time
No-Code, Centralized Access Management






